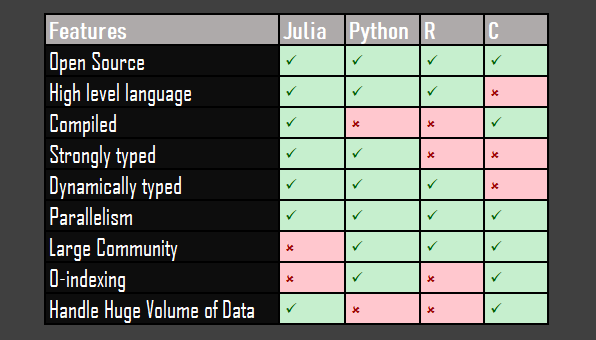
Dans de nombreux langages, y compris C et Python, les premiers éléments des tableaux sont accessibles avec un zéro. Par exemple, en Python, le premier caractère d’une chaîne est une chaîne [0]. Lorsque vous utilisez Julia, vous devez gérer l’indexation 1. Ce n’est pas une décision arbitraire, de nombreuses autres applications mathématiques et scientifiques, comme Mathematica, utilisent l’indexation 1, et Julia est destiné à plaire à ce public. Heureusement, il existe une fonctionnalité expérimentale qui permet la prise en charge de l’indexation nulle, mais l’indexation 1 par défaut peut empêcher l’adoption par un public plus généraliste avec des habitudes de programmation enracinées.